Chapitre 6 : Estimation
2 Distribution d’échantillonnage
Pour résoudre les problèmes d’estimation de paramètres inconnus, il faut tout d’abord étudier les distributions d’échantillonnage, c’est à dire la loi de probabilité suivie par l’estimateur.
| Remarque : | En théorie de l’estimation, il s’agit de distinguer soigneusement trois concepts différents : |
|
- les paramètres de la population comme la moyenne m dont la valeur est certaine mais inconnue symbolisés par des lettres grecques. - les résultats de l’échantillonnage comme la moyenne dont la valeur est certaine mais connue symbolisés par des minuscules. - les variables aléatoires des paramètres, comme la moyenne aléatoire dont la valeur est incertaine puisque aléatoire mais dont la loi de probabilité est souvent connue et symbolisées par des majuscules. |
2.1 Définition
2.1.1 Approche empirique
Il est possible d’extraire d’une population de paramètres p, m ou s2 pour une variable aléatoire X, k échantillons aléatoires simples de même effectif, n. Sur chaque échantillon de taille n, on calcule les paramètres descriptifs (f, , s2).
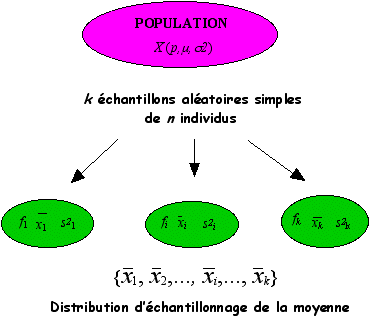
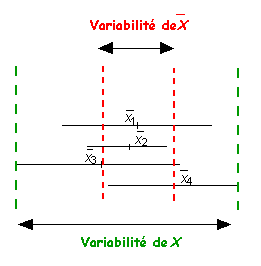
On obtient ainsi pour chaque paramètre estimé, une série statistique composée de k éléments à savoir les k estimations du paramètre étudié. Par exemple, on aura k valeurs de moyennes observées (graphe ci-dessus).
La distribution associée à ces k estimations constitue la distribution d’échantillonnage du paramètre. On peut alors associer une variable aléatoire à chacun des paramètres. La loi de probabilité suivie par cette variable aléatoire admet comme distribution, la distribution d’échantillonnage du paramètre auquel on pourra associer une espérance et une variance.
2.1.2 Approche théorique
En pratique, les données étudiées sont relatives à un seul échantillon. C’est pourquoi, il faut rechercher les propriétés des échantillons susceptibles d’être prélevés de la population ou plus précisément les lois de probabilité de variables aléatoires associées à un échantillon aléatoire.
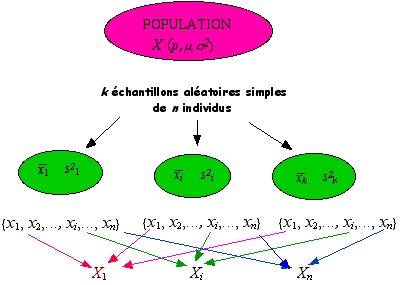
Ainsi les n observations x1 , x2 ,…, xi , ..., xn, faites sur un échantillon peuvent être considérées comme n variables aléatoires X1 , X2 ,…, Xi , ..., Xn. En effet, la valeur prise par le premier élément extrait de la population X1, dépend de l’échantillon obtenu lors du tirage aléatoire. Cette valeur sera différente si l’on considère un autre échantillon. Il en est de même pour les n valeurs extraites de la population.
A partir de ces n variables aléatoires, on peut définir alors une nouvelle variable qui sera fonction de ces dernières telle que :
Y = f(X1, X2,…, Xi , ..., Xn )
par exemple : Y = X1 + X2+…+ Xi +. …Xn
Ainsi la loi de probabilité de la variable aléatoire Y dépendra à la fois de la loi de probabilité de la variable aléatoire X et de la nature de la fonction f.
2.2 Loi de probabilité de la moyenne
2.2.1 Définition
Soit X une variable aléatoire suivant une loi normale d’espérance m et de variance s2 et
n copies indépendantes X1,X2,…,Xi,…,Xn telle que Xi associe le ième élément de chacun des n échantillons avec E(Xi) = m et V(Xi) = s2.
On construit alors la variable aléatoire , telle que
avec pour espérance :